
Python web scraping using urllib
In this article, you will learn about web scraping using the Python urllib library.
Web scraping is the process of extracting data from websites. The extracted data can be content, urls, contact information, etc, which we can store in a local file or database. This process can be done manually by a code called a scrapper or by automated software implemented using a bot or web crawler. The Web scraping is not always legal. Some sites disallow the scraping in the 'robots.txt' file. Some popular sites provide APIs to access their data in a structured way. But not all websites. So, we need a web scraper for data extraction, data mining, and storing in a structured way.
Python is the most popular programming language for web scraping. It provides many libraries that can handle web crawler related process smoothly. In this article, we are using the urllib library.
Install urllib
We don’t need to install it, because it is already installed in Python 3. To use this, we only need to import it like following in Python3.
import urllib.requestFor Python2, use the following to import the module.
import urllib2Install lxml module
In Python, there are several libraries to parse data from web resources. The lxml is one of those that has strong performance in parsing very large files. We can easily install this using the pip tool.
pip install lxmlOn successful installation, it returns something like this-
Collecting lxml
Downloading lxml-4.5.0-cp37-cp37m-win_amd64.whl (3.7 MB)
|████████████████████████████████| 3.7 MB 384 kB/s
Installing collected packages: lxml
Successfully installed lxml-4.5.0Python urllib web scraping examples
These are the various web scraping examples using the Python urllib library.
Python extract web content
To get started, find the URL you want to extract the data from. Suppose we have taken a Twitter search URL. Next, open it with urllib.request and parse the stream with lxml like so-
from lxml.html import parse
from urllib.request import urlopen
parsed = parse(urlopen('https://twitter.com/search?q=python%20pandas&src=typed_query'))
doc = parsed.getroot()
links = doc.text_content()
print(links)The above code returns the content of the specified URL. The parsed.getroot() extracts all the HTML tags.
Python extract all URLs
In the given example, we have extracted all the URLs from a website using Python urllib library.
from lxml.html import parse
from urllib.request import urlopen
parsed = parse(urlopen('https://twitter.com/search?q=python%20pandas&src=typed_query'))
doc = parsed.getroot()
urls = [lnk.get('href') for lnk in doc.findall('.//a')]
print(urls)
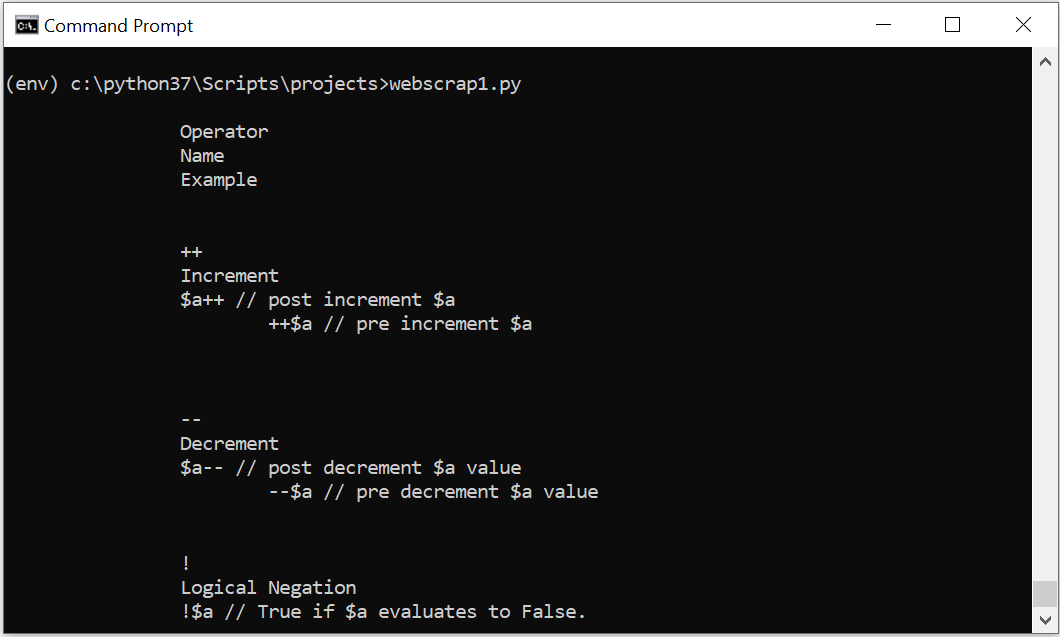
Python scrap HTML table
To parse the table, find all table elements and grab their rows. In the given example, we have taken the second table element and found all their rows. Next, we loop over it and get the data.
from lxml.html import parse
from urllib.request import urlopen
parsed = parse(urlopen('https://www.etutorialspoint.com/index.php/tutorial/php-operators'))
doc = parsed.getroot()
tables = doc.findall('.//table')
calls = tables[1]
rows = calls.findall('.//tr')
for row in rows:
print(row.text_content()) When we execute the above code, it returns the following output-
Related Articles
Python requests GET methodHow to convert MySQL query result to JSON in Python
How to display data from MongoDB in HTML table using Python
CRUD operations in Python using MongoDB connector
Write Python Pandas Dataframe to CSV
Quick Introduction to Python Pandas
Python Pandas DataFrame
Python3 Tkinter Messagebox
Python get visitor information by IP address
Python Webbrowser
Python Tkinter Overview and Examples
Python Turtle Graphics Overview
Factorial Program in Python
Python snake game code with Pygame
Python JSON Tutorial - Create, Read, Parse JSON file
Python convert xml to dict
Python convert dict to xml



